Интернационализация и локализация
Привет!
Я задумывал этот блог как более серьезный по сравнению с моим первым блогом. В целях расширения охвата я принял решение писать статьи на английском языке. Однако, все же некоторую часть статьи лично мне проще сформулировать на русском, а затем перевести на английский. Таким образом, после каждой публикации в моей “кузне” остается довольно много материала, который можно было бы немного причесать и опубликовать, но, к сожалению, технической возможности сделать это до недавнего времени не было.
Итак, сегодня я расскажу о том, как я проапгрейдил свой блог, чтобы он начал поддерживать мультиязычность, а также расскажу о проблемах, с которыми столкнулся.
Теория
Минутка душноты, как обычно.
Интернационализация — это процесс разработки программных приложений, которые потенциально могут адаптироваться к различным языкам и регионам без инженерных изменений.
Локализация — это процесс адаптации интернационализированного программного обеспечения для определенного региона или языка путем добавления локальных компонентов и переведенного текста.
В этом проекте я занимался и тем, и тем.
Данные
Разработка (имеется ввиду этап, когда мы уже перешли к написанию кода) любой фичи в моем блоге начинается с типов. Будь то пропсы компонента, DTOs или модель базы данных. Все это описывается с помощью TypeScript. Такой подход обеспечивает довольно очевидный эффект - при изменении в одном месте что-то разваливается в другом и, обычно, остается только починить нужным образом, чтобы фича заработала.
Я веду разработку блога в монорепозитории, поэтому и api, и web-client сервиса лежат в одном Git репозитории. Также, у меня есть модуль shared, в нем описаны различные project-wide константы (например существующие роли, а теперь и поддерживаемые языки), а также DTO. В итоге, и контроллеры в API, и data-layer в React компонентах используют одни и те же типы. Хочу подчеркнуть, что shared модуль представляет собой просто папку, откуда просто импортируется то, что нужно. Не NPM пакет, не что-либо еще, а обычная папка c TS файлами.
Для обращения к БД я использую SQL query builder Kysely. Примерно так это выглядит:
const { id } = await pg
.selectFrom('articles')
.select(['id'])
.where('slug', '=', slug)
.executeTakeFirst();Этот запрос достанет idslugJOIN или подзапросами). А так как каждый контроллер знает какой тип он должен отдать на клиент получается, что весь проект, несмотря на то, что разворачивается каждое приложение по отдельности, составляет единую систему.
В плане подходов к разработке фичей в моем блоге, данный случай, конечно, не стал исключением. В первую очередь, для поддержки мультиязычности в структуру БД пришлось внести довольно большие изменения. Все, что может быть локализовано переехало в отдельную табличку, и в итоге у каждой ArticleArticleContentlangarticle_id
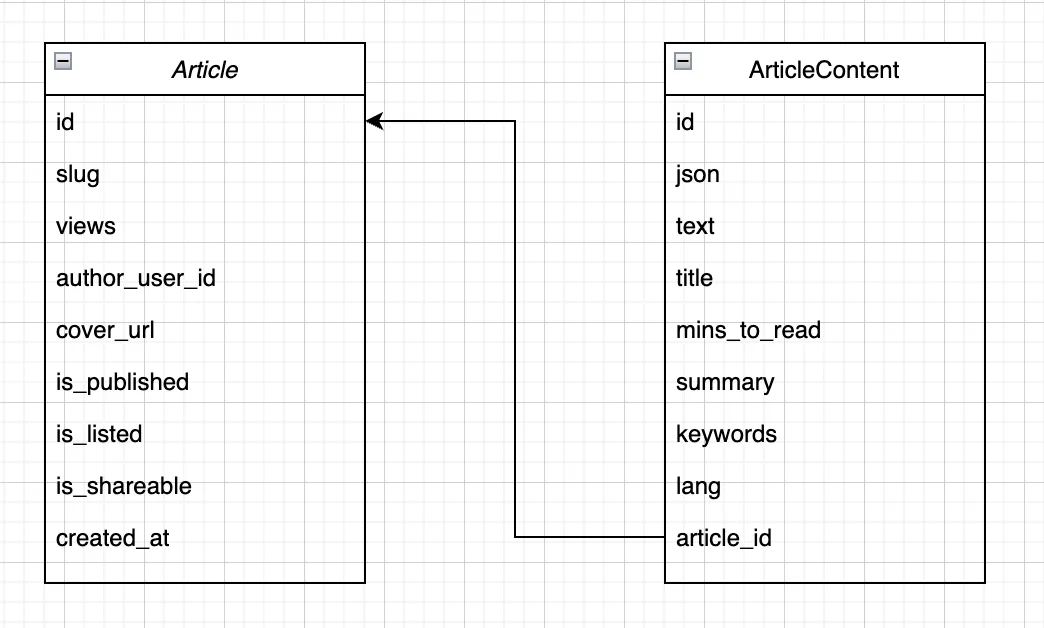
Я решил не заводить отдельную таблицу Languageslangvarchar
После обновления схемы данных развалились почти все контроллеры, которые были на нее завязаны, я починил все ошибки и местами обновил также DTO. После обновления DTO посыпались ошибки уже со стороны клиентской части, они также были починены и на самом деле мультиязычные статьи к этому моменту были уже готовы. Хотя, в этом проекте предстояло еще много работы по переводу интерфейса, об этом расскажу далее.
Шрифт
Когда я придумывал этот блог, я хотел, чтобы он выглядел строго. Может быть даже как какое-нибудь печатное издание. Я перепробовал несколько шрифтов и мой выбор пал на Libre Baskerville.
Baskerville — это шрифт с засечками (serif), разработанный в 1750-х годах Джоном Баскервиллем (1706–1775) в Бирмингеме, Англия. Baskerville классифицируется как переходный шрифт, задуманный как усовершенствование того, что сейчас называют шрифтами старого стиля того периода.
Libre Baskerville — это веб-шрифт, оптимизированный для основного текста. Он основан на шрифте American Type Founder's Baskerville 1941 года, но имеет более высокую x-height, более широкие counters и немного меньший контраст, что делает его хорошо подходящим для чтения на экране.
Этот шрифт очень мне нравится и на мой субъективный взгляд очень хорошо подходит для моего блога. Однако, в ходе проектирования данной фичи было выяснено, что Libre Baskerville не поддерживает кириллические глифы. То есть при попытке отрендерить текст с русскими буквами шрифт фоллбэкнется на serif (скорее всего, это будет Times New Roman) и это будет выглядеть, мягко говоря, не очень:
Конечно, это никуда не годится, поэтому я стал искать пути решения этой проблемы. Я перепробовал с десяток бесплатных шрифтов, похожих на Libre Baskerville, однако мои поиски не увенчались успехом. Тогда я даже подумал о том, чтобы приобрести платную версию шрифта Baskerville на сайте Paratype. За два начертания мне пришлось бы выложить 60 долларов, плюс там есть дополнительные сложности типа увеличивающейся стоимости подписки в зависимости от просмотров страницы, а еще довольно странное требование “May not use the font to create content by visitors to your websites”. Это довольно странно, потому что в моем случае это требование как будто бы ограничивает использование шрифта в форме для написания комментариев.
В общем, довольно много сомнительных и непонятных моментов, да еще и деньги придется платить, причем 60 долларов это относительно много, это примерно полгода оплаты услуг за хостинг, поэтому и этот вариант я отмел.
В итоге не оставалось ничего другого кроме как взять Libre Baskerville, благо он распространяется под OFL, и дорисовать кириллические глифы. Я подумал, что это не очень сложно, к тому же некоторые буквы выглядят так же как и латинские и их можно просто скопировать. На самом деле это и правда несложно, но это довольно большой объем очень кропотливой работы. Конечно же, я понимаю, что я не прочувствовал на себе создание шрифта с нуля. У меня уже были готовые гайдлайны от авторов Libre Baskerville и даже некоторые буквы для сравнения. Честно говоря, думаю, что с нуля шрифт я бы не смог создать.
Так, потихоньку я рисовал букву за буквой. В итоге было нужно нарисовать 33 * 2 (заглавные + строчные) * 2 (regular + bold) = 132 буквы. Некоторые буквы я скопировал без изменений, некоторые сделал из других (например П легко сделать из Н, а Ж из двух К). Некоторые же пришлось прям почти с нуля рисовать (например Ф или Л), этим объясняется то, что данные буквы вышли чуть более кривыми, чем остальные. Хотя, по правде говоря, все буквы получились кривоватыми, это лучше чем фоллбэк на Times New Roman и в целом результат меня устроил.
Я использовал Glyphr Studio и, в целом, это довольно удобная программа, но иногда у нее течет память и она вылетает, так что приходилось сохранять каждый раз, когда очередная буква была нарисована. Увы, кое-что все таки приходилось рисовать дважды.
А Вам, уважаемые читатели, прямо сейчас совершенно бесплатно доступны два этих замечательных шрифта (лицензируется OFL):
- Лицензия
Интерфейс
С интерфейсом все куда проще. Я использую react-intl для интернационализации. В коде используются ключи, затем по ключу в зависимости от языка подставляется нужный перевод. Также, из коробки поддерживаются плюрализация и подстановка значений, а также форматирование времени, дат, чисел и так далее.
Но хочу рассказать о некоторых практиках, которые помогут сделать работу с переводами проще.
Первая рекомендация - это хранить переводы рядом с компонентом. Давайте рассмотрим на примере компонента ArticleStats
📦ArticleStats
┣ 📂__Icon
┃ ┗ 📜ArticleStats__Icon.css
┣ 📂__Name
┃ ┣ 📜ArticleStats__Name.css
┃ ┗ 📜ArticleStats__Name.tsx
┣ 📂__Stat
┃ ┣ 📜ArticleStats__Stat.css
┃ ┗ 📜ArticleStats__Stat.tsx
┣ 📂__Value
┃ ┣ 📜ArticleStats__Value.css
┃ ┗ 📜ArticleStats__Value.tsx
┣ 📂ArticleStats.helpers
┃ ┗ 📜capitalize.ts
┣ 📂ArticleStats.i18n <- папка с переводами
┃ ┣ 📜ArticleStats.en.json
┃ ┗ 📜ArticleStats.ru.json
┣ 📜ArticleStats.css
┗ 📜ArticleStats.tsxВ файле ArticleStats.en.json лежат ключи в таком виде:
{
"ArticleStats.published": "Published",
"ArticleStats.views": "{views, plural, one {view} other {views}}",
"ArticleStats.mins": "{mins, plural, one {min} other {mins}}"
}В итоге все файлики переводов для одного компонента лежат в одном месте, а воедино их легко собрать простым скриптом на Node.js. Затем этот один большой файл читается на сервере и в память загружаются сразу все переводы для всех языков, а на клиент при SSR отдаются ключи только для нужного языка. Хочу заметить, что все ключи префиксятся именем блока, это нужно для того, чтобы уменьшить вероятность возникновения коллизий.
Второе, что я мог бы посоветовать - это запретить использование чего угодно, кроме строковых литералов при указании ключей. Поясню. Чтобы получить строку в react-intl, вы должны отрендерить элемент FormattedMessage
<FormattedMessage id="ArticleStats.published" />или вызвать метод intl.formatMessage:
intl.formatMessage({ id: 'ArticleStats.published' })И иногда я видел варианты с шаблонными строками, тернарными операторами и это на самом деле все только усложняет.
Например, вместо:
<FormattedMessage id={`ArticleStats.${action}`} /> // action: 'published' | 'created' | 'updated'Гораздо лучше написать:
const actionsMap = {
published: <FormattedMessage id="ArticleStats.published" />,
created: <FormattedMessage id="ArticleStats.created" />,
updated: <FormattedMessage id="ArticleStats.updated" />
};
<div>
{actionsMap[action]}
</div>Код стал чуть посложнее (хотя и не сильно), зато теперь такие вызовы можно искать хоть обычными регулярками, не говоря уже о запросах по AST (вот тут можно поиграться с этим). Статический анализ кода в данной ситуации очень полезен, потому что так у Вас будет возможность сразу узнать о том, какие ключи не используются, чтобы их удалить! Кода становится меньше, бандлы становятся тоньше и ничего лишнего - красота.
На самом деле, можно еще больше улучшить DX (не придется запускать странные скрипты и разработчик сразу будет узнавать о проблеме), написав кастомное правило для ESLint. Автофиксить его, скорее всего, не получится, но и поправить такое место будет нетрудно. В большинстве случаев подобные сложные выражения раскрываются в хэшмап, либо switch-case. Если же ключа два, то можно продолжить использовать тернарный оператор, просто снаружи, а не внутри.
Алгоритм
В первую очередь смотрим на query параметр langAccept-LanguageAccept-Language не указан ни один поддерживаемый язык, то выбирается английский (en).
После определения языка происходит “залипание” на него с помощью куки. После этого сменить его можно будет только явно перейдя на страницу с параметром lang
SEO
Поисковой робот должен знать о том, что на моем сайте поддерживается мультиязычность. При запросе страницы без query параметров GoogleBot’у (или другому поисковому роботу), будет отдаваться версия на английском (он не передает куки и заголовок Accept-Language), а значит алгоритм будет фоллбэкаться на en.
Для того, чтобы сообщить язык текущей страницы используется атрибут lang у элемента html.
А для ссылок на другие страницы используется элементы link с атрибутом rel равным alternate. Выглядит это вот так:
<link rel="alternate" hreflang="en" href="https://vladivanov.me/"> <!-- на себя саму тоже нужна ссылка -->
<link rel="alternate" hreflang="en" href="https://vladivanov.me/?lang=en">
<link rel="alternate" hreflang="ru" href="https://vladivanov.me/?lang=ru">Выкатка
Kysely умеет генерировать миграции, но в итоге и изменение структуры, и переливку данных я делал вручную прям в контейнере с БД на проде с помощью psql😁. Сначала я завел новую таблицу, завел индексы для поиска, сделал дамп таблицы Articles
Вся фича с мультиязычностью была внесена под фичефлаг и обычные пользователи не могли ей воспользоваться, после тестирования и создания в админке версий для всех статей на русском, я вынес фичу из под фичефлага, но пока отключил определение языка по заголовку Accept-Language.
Сейчас вместе с этой статьей фича начала работать согласно описанию, в интерфейс была добавлена кнопка для переключения языка, а чуть позже я сделаю email рассылку для подписчиков. Это довольно значимое событие в истории развития моего блога.
Заключение
Это был крайне захватывающий проект, с учетом того, что он охватил весь спектр работ. А это и разработка, и администрирование БД и даже вопросы касательно дизайна (типографии). Я очень рад, что в моем блоге появилась мультиязычность, а еще я рад поделиться с Вами этим замечательным и ярким опытом.
Пишите в комментарии, если Вам интересно как работает мой блог, я готов рассказать Вам о любой его части.
Спасибо за внимание!